我们在做日志分析时,都会发现有不同的搜索引擎(百度)蜘蛛IP。有时候这些IP是搜索引擎(百度)蜘蛛正常访问留下的;但也有时候,这些IP并不是搜索引擎(百度)蜘蛛留下的IP,可能是某些同行采集后留下的,或者是其他工具留下的。
那么如何判断如何判断搜索引擎(百度)蜘蛛IP的真假呢?以百度蜘蛛为例。有以下两种方式(以220.181.108.140和117.28.255.37为例):
一、通过IP地址辨别真假:
在IP查询输入框中直接输入IP,输入:220.181.108.140,显示如下图所示,说明是真正的百度蜘蛛;
输入:117.28.255.37,显示的是如下图所示的,则表明不是真正的百度蜘蛛。
二、通过指令甄别:
1、windows平台下:
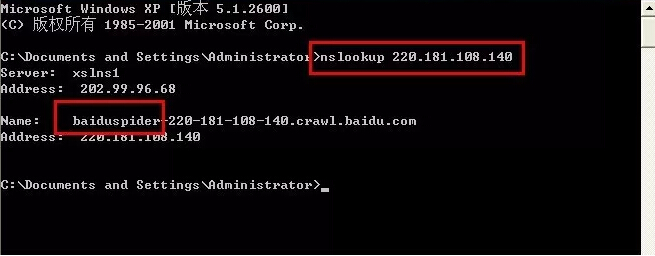
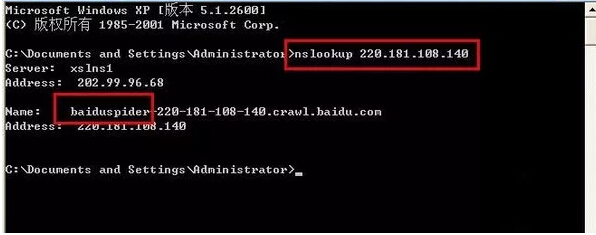
依次点击“开始―运行”,输入“cmd”,使用命令“nslookup +ip(要查询的IP)”查询,输入:220.181.108.140,如下图所示,表明是正常的百度蜘蛛;
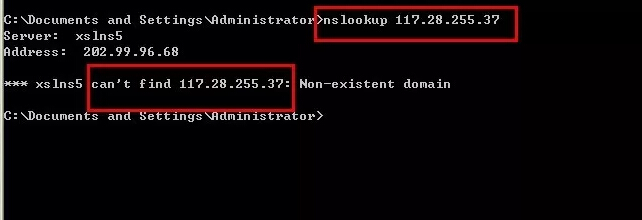
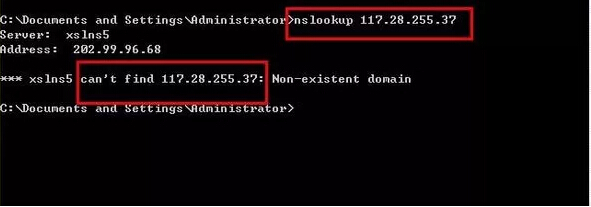
输入:117.28.255.37,如下图所示的,则表明不是真正的百度蜘蛛。
只要是正常搜索引擎的蜘蛛,代码中会有出现:name:蜘蛛名(如:name:baiduspider);如果没有出现,那就不说不是真的百度IP段。
2、linux平台下:
host ip命令反解ip来判断是否来自Baiduspider的抓取。Baiduspider的hostname以 *.baidu.com 或 *.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充。
3、mac os平台下
可以使用dig 命令反解ip来 判断是否来自Baiduspider的抓取。打开命令处理器 输入dig xxx.xxx.xxx.xxx(IP地 址)就能解析ip, 来判断是否来自Baiduspider的抓取,Baiduspider的hostname以 *.baidu.com 或*.baidu.jp 的格式命名,非 *.baidu.com 或 *.baidu.jp 即为冒充。
以上两种策略方法对于其它搜索引擎蜘蛛的判断同样适用!







